Here is a small example of that illustrates some of the components of BigGorilla.
Data Acquisition and Data Extraction:
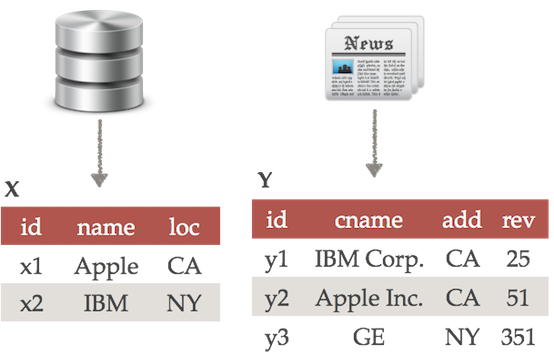
Suppose we have acquired a table X(id, name, loc) from a relational database management system and we have extracted a table Y(id, cname, address, rev) from a set of news articles.
The table X contains information about the names and locations of companies while the table Y contains, for each company, its address and its quarterly revenue of the company in billions of dollars.

DATA CLEANING:
We detect that revenue 351 of GE (the last row of Table Y) is an outlier. Upon closer inspection, we realize that it should have been 35.1 instead of 351, due to an extraction error. So we manually change this value to 35.1.
* Note that there are many other types of cleaning operations in general. We are currently missing a data cleaning component in BigGorilla.
SCHEMA MATCHING:
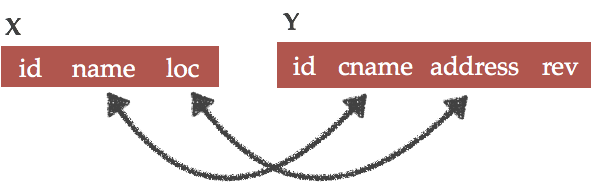
Next, we match the schemas of tables X and Y. We obtain the matches name⬌cname and loc⬌address. Intuitively, this means that the attribute name of table X is the same as cname of table Y, and the attribute loc of table X is the same as address of table Y.

SCHEMA MERGING:
Based on the matchings name⬌cname and loc⬌address between tables X and Y, the data scientist may choose to merge the two schemas X(id, name, loc) and Y(id, cname, address, rev) into a single schema Z(name, loc, rev). Note that the id attribute is omitted in the merge process and this is a conscious decision of the data scientist.
DATA MATCHING:
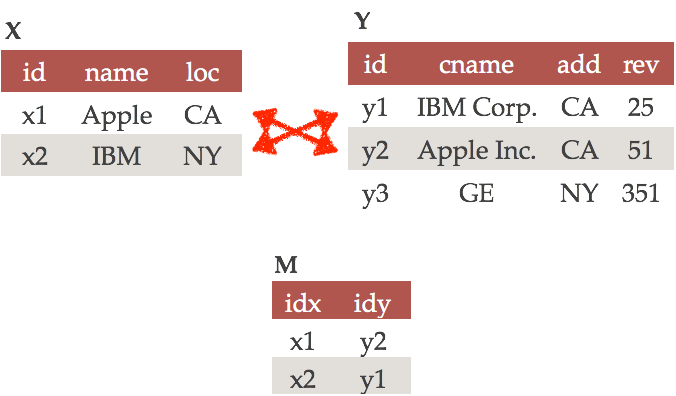
Next, we match the tuples of tables X and Y. The matching process makes the follow associations: x1 ≃ y2 and x2 ≃ y1. Intuitively, the first match x1 ≃ y2 indicates that tuple x1 and tuple y2 refer to the same real-world entity (in this case, they are the same company Apple Inc.). Similarly, tuple x2 and y1 refer to the same company IBM Corp. These matches are stored in a table M.
DATA MERGING:
We now decide now to merge the tuples that refer to the same entity. For example, to merge x2 = (IBM, NY) and y1=(IBM Corp., CA, 25) into one tuple that conforms to the schema Z(name, loc, rev) according to the matchings name⬌cname and loc⬌address, we will have to make a decision on what to do with the conflicting values “IBM” vs. “IBM Corp.” for the name attribute and what to do with the conflicting values “NY” vs. “CA” for the loc attribute.
For name, we may choose to write a heuristic to prefer the longer string (i.e., “IBM Corp.” in this case) as longer strings tend to be more formal and informative. For loc, we may choose to write a rule that will always select from the first table (i.e., “NY” in this case) as table X is a high-quality curated relational database.
Naturally, there are other ways to merge the data. Typically, data scientists write heuristic rules based on their knowledge about the domain and the sources.
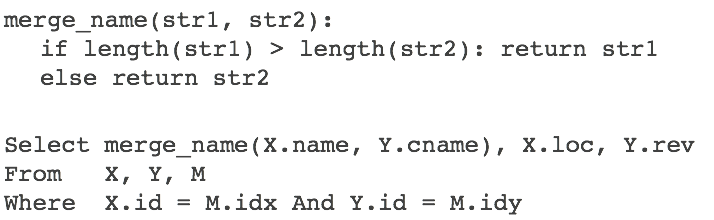

SCHEMA MAPPING:
The program that is used to transform data that resides in tables X and Y into table Z is called a schema mapping. Here, the schema mapping is developed based on understanding how tuples from X and Y should be migrated into Z. The program can be an SQL query that populates table Z based on tuples from tables X and Y. It uses table M to determine the matches and it uses the function merge_name(.) to apply the heuristic of selecting the longer string described earlier.
Discussion Points
The example above is simplified to illustrate the key steps of data integration and data preparation. In practice, the steps may be carried out in a different order and some of the steps may even be repeated. For example, once table Z is obtained, the data may be cleaned again and matched and merged with some other datasets. Also, instead of discarding information about the last tuple in table Y, the data scientist may choose to keep the last tuple by performing an outer join in the SQL query.
In general, many of the steps such as schema matching/merging and data matching/merging are not as trivial as the example shows. Hence, the schema mapping and the process of arriving at the desired schema mapping are not as trivial as what is illustrated above. To make it easy for a data scientist to wrangle data, it is important to have semi-automatic tools to help the data scientists along each step.
The example above covers the “data wrangling” aspect of the data science pipeline. After data from different sources are integrated into a single database, a data scientist would like to perform analysis on the data through techniques such as classification, clustering, anomaly detection, correlation discovery, and OLAP style exploration.