Contributing Workflows
You can contribute to the collection of workflows in BigGorilla by sharing any data-preparation code in Python or Jupyter notebook format. The contributors can share their workflows through BigGorilla’s Github repository. If you are new to contributing to open-source projects, the following beginner’s guide might be of help.
Step 1 (Fork):
Navigate to BigGorilla’s Github repository with a browser, and click on the “fork” button to create a copy of BigGorilla’s repository in your Github account.

Step 2 (Clone):
Clone a local copy of the forked repository by entering the following command:
>> git clone https://github.com/<your_username>/
Step 3 (Add Upstream):
Note that the current remote repository for the project is the copy you forked from the BigGorilla repository. Using the next command, specify that this project has another remote which is the original BigGorilla repository. (Enter the command in the “biggorilla” directory.) The new remote is called “upstream”.
>> git remote add upstream https://github.com/biggorilla-gh/biggorilla.git
Step 4 (Edit):
Make sure to pull the latest changes from BigGorilla’s repository using the following command:
>> git pull upstream master
Next, create a new branch to work on. Let’s call this branch “new_workflow”.
>> git checkout -b new_workflow
Make changes as you see fit (i.e., add, remove, or edits files), and push the changes to your branch.
>> git push origin new_workflow
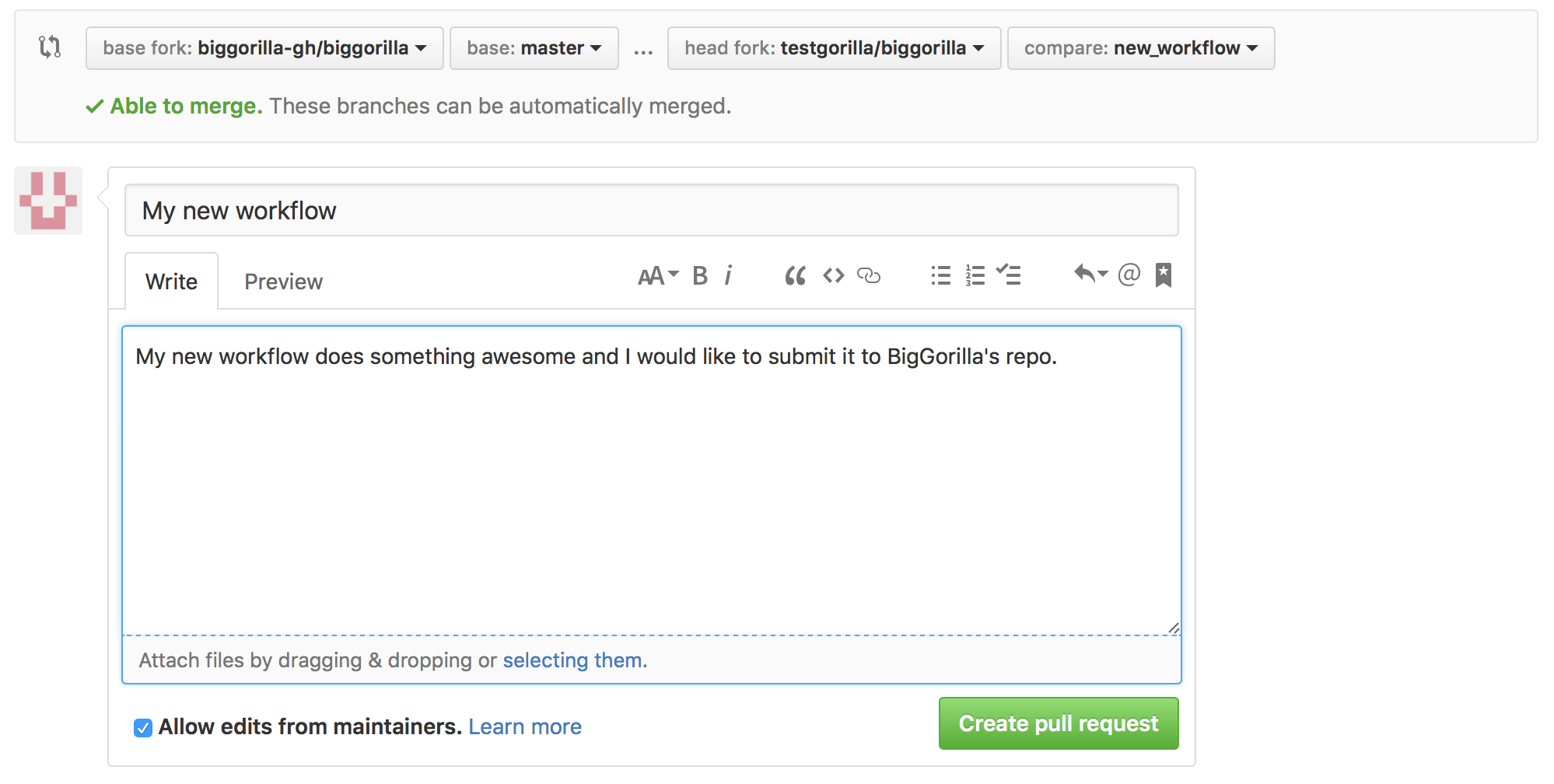
Step 5 (Pull Request):
Now, you can request BigGorilla to reflect your changes in their repository. To do so, browse to your forked repository on Github. Click on the “Pull request” button to send a pull request to the BigGorilla’s team.

Finally, provide a description of your contribution and submit the request.
Contributing Packages
Python packages can also be submitted to the BigGorilla’s repository using the same steps mentioned above. However, if you have already developed a Python package which is in the PyPi repository, you can email us at website@biggorilla.org to tell us about the package and how it is relevant to data-preparation and data integration tasks. A brief guide on how to create a python package can be found here.